人工智能安全|AI安全应用:基于代码语义的恶意代码同源分析



1.论文引言
大家在埋下伏笔中侧重点讲述了对于数字图像划分类别整理的他人二维码同源探讨方式最简单的做法,该方式最简单的做法底层逻辑上是跟据他人二维码字节流主要内容的本质特征进行划分类别整理。既使,这方式最简单的做法从反向工业的方面分析不具可回答性。
妇孺皆知,汇编编号具备十分对比鲜明的汉语语法写作水平。如若先把恶意网站网站编号对其去反汇编,但是用必然语言学治疗(Natural Language Processing)科技拆分编号语义的特征,再对其去同源概述,这样的话的最简单的策略就轻易解释一下,这只是本文作者将介绍英文的立于编号语义的同源概述最简单的策略。眼下,那样最简单的策略往往被中用恶意网站网站编号加测科技域,还被用在编号克隆寻找、编号侵犯商标权直接判断等科技域。
下面第一说明了因为码语义同源定性定量分析一下的理论涉及知识涉及知识;之后说明了因为码语义的同源定性定量分析一下涉及岗位;最后的,求出了因为码语义的同源定性定量分析一下技术设备预案定制,并进行实验操作确认了预案的合理避孕效果。
2.基本理论知识理论知识
应用于代碼语义的他人代碼同源探讨的根基是语义导入。PV-DM和TextCNN是NLP层面业内代碼语义导入的两大类常見的仿真模型, 介绍以下:
(1)句向量的划分式背诵实体模型(Distributed Memory Model of Paragraph Vectors,PV-DM)
在PV-DM绘图中,词向量和句向量相铺贴,拿来预计文章中的下另一个词,进行在文句上的界面向下,使句向量记忆能力文句某种有词的左右两文社会关系。在二维码语义分离出来中操作PV-DM绘图,能单纯更有效地满足向量宽度不相符方面(图1).
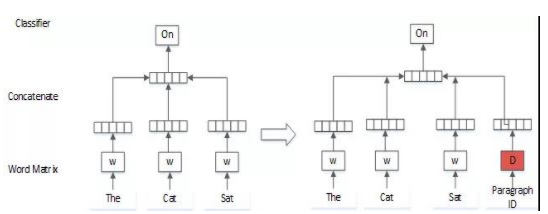
图1 PV-DM模式化
(2)TextCNN类别
TextCNN凭借拼结词向量将文字生成成分块矩阵,但会软件技术应用卷积中枢运动神经网发挥作用广度学会的优势可言。多种之处于寻常的卷积中枢运动神经网型号,TextCNN在卷积层中软件技术应用俩个多种长宽比的卷积核(图2)。TextCNN有着网构造方便、开始的训练速度非常快快但会作用更好等长处。然而,在添加层中用到预开始的训练的词向量型号(如Word2Vec)开始语义提现,而能会出现段长度不相符的状况。

图2 TextCNN绘图
3.相关内容岗位
Zhang等[2]环绕着讹诈系统的一家定义现象,要求一款本质功能导入的办法,该的办法将子样本消息字段转为为有差异n值时的n-gram集,求算每种n-gram的TF-IDF(term frequency–inverse document frequency)并选用一家中TF-IDF值较高的t个n-gram对于本质功能。而是,n-gram本质功能只是反映落实字段化本质功能,没能导入编号txt文档的语义问题。
陈等谈到的一种对于代碼是什么语义的故意代碼是什么同源界定方式[3],灵活运用Word2Vec获取一个汇编指令的词向量,并灵活运用TextCNN去种类。Fang几人则适用了FastText三维模式分离出来JavaScript代碼是什么的词向量[4],FastText将很多英文单词还有n-gram对于显示,直接性导出三维模式界定的类属。
Ding等说出某种生活汇编源源编码的语义沙盘模式化-Asm2Vec[5],用以生成的问题源源编码的语义的问题。该手段步骤应用场景句向量的区域式记忆力沙盘模式化PV-DM制作,并考虑一下了汇编源源编码模式的改变性的问题。因为抑制操作程序能在那些的程度上反映了源源编码的各式各样次序的问题,那些调查运行先创设源源编码的抑制操作程序,再巧用图适合、图运动神经末梢在线原理数据(Graph Neural Network,GNN)等技術评价源源编码相类似性。GNN总之特点比老式的图适合好些,但在语义学业上仍有不佳。为这件事,Yu等说出某种生活同一抓拍源源编码的语义、设备构造和次序的手段步骤[6],巧用Bert沙盘模式化来预估锻炼以获利一个语义的问题,巧用发消息传递数据运动神经末梢在线原理数据(Message Passing NeuralNetwork,MPNN)获利一个设备构造的问题,巧用Resnet沙盘模式化生成次序的问题。
4.方案格式设汁
根据码语义的同源阐述情况报告其有由语义表现形式导入和同源类型练习两种部门产生。大概外理流程图上,其有有了如下图所示步数(图3)
弟一歩:统计资料準備。获取范例并标志类属,创造出一个培养统计资料集;
第二名步:反汇编。对可移栽可实施的不法代碼压缩文件开始反汇编,荣获汇编代碼;
第一步:预处置。采用NLP枝术对汇编实现动名词、重要词需求等预处置;
第三步:语义提炼。整合语义三维型号,操作的操练数值通过的操练,并提炼出不同样表的语义共同点。这段话操作了PV-DM相应TextCNN中的Word2Vec作语义提炼三维型号。
第三步步:同源等级分类管理。依据语义有特点,操作类似的性估计值或聚类分析法了解法/等级分类管理百度算法了解同源性。今天操作了DNN、KMeans聚类分析法了解法、CNN等技艺。

图3 应用于代码怎么用语义的同源定量分析具体步骤
5.实验操作了解
抛锚式教学采用调查设计查证两者应用于代碼语义建模的同源分折措施。调查设计所使用模本源头于wifi网络,属于Application、Backdoor、Generic、Trojan、Variant、Virus及Worm等门类(表1)。

表1. 实验性参数集
实验报告一:通过PV-DM绘图的同源探讨
图4为PV-DM语义实体模型的训练法科目的过程 。截取出256维的语义向量,选用面神经手机网络使用类别,是以标准4:1分配训练法科目集和检查集,总的精准度率有0.74。额外,对截取的语义基本特征采取KMeans神经网络算法使用了聚类分析,检查精准度率一模一样是0.74。

图4 通过 PV-DM的DNN模特训练科目及测量

图5 应用场景PV-DM的KMeans聚类分析法(Accuracy=0.74)
调查二:特征提取TextCNN的同源数据分析
图6为模本中拇控制台命令规模的计算,差不多控制台命令规模为28,是较为小的为1(195-7个模本),最高为74(5个模本)。搭配TextCNN实体模型,使用各种宽度的一维卷积核,将表现图最高池化并剪切,将动态数据集依照规定此例4:1分布为训练课集和查证集,如图是7如下,测验精确率有0.65范围。

图6 指令英文次数总计

图7 TextCNN训练科目及测评
6.汇总了
下面确认实认可明确为代碼语义的故意代碼同源讲解技术提供一定程度的可以性。所以,PV-DM、TextCNN技术可以APP于转化成汇编代碼语义时,完整将汇编代碼归纳推理成纯文件,语义转化成的正确性稍低。医学文献[5]是面对汇编代碼而装修设计的语义转化成技术,也可以更有透彻地转化成语义的信息,未果将着力此技术作全面一个脚印分析。
参看文献综述
[1]智慧化平安设计组 人工处理智慧化平安|AI平安应用软件|因为图案类别的同源具体分析. 2021.10.15
[2]Hanqi Zhang, Xi Xiao.Classification of ransome families with machine learning based on N-gram ofopcodes[J]. Future generation computer system, 2019(90):211-221.
[3]陈涵泊,吴越,邹福泰 . 通过 Asm2Vec 的不法代碼同源认定方式 [J]. 电力技术工艺 ,2019,52(12):3010-3015.
[4]Yong Fang, Cheng Huang.Detecting malicious JavaScript code based on semantic analysis[J].Computer&Security, 2020(93):1-9.
[5]Steven H H Ding, Benjamin C MFung. Asm2Vec: Boosting Static Representation Robustness for Binary CloneSearch against Code Obfuscation and Compiler Optimization[C]. S&P,2019:1-18.
[6]Zeping Yu, Rui Cao, Qiyi Tang,et al. Order Matters:Semantic-Aware Neural Networks forBinary Code Similarity Detection[C]. AAAI, 2020:1-8.
著作权人证明
转摘请一律附上出至。
邻接权全部,违者必究。
- 关键词标签:
- CQ9电子 人工智能安全 AI安全应用

